Two-tier agents: the cost and quality argument
Two-tier AI agents — a cheap triage classifier in front of a deep LLM extractor. Cost, precision, and governance benefits, with the full design pattern.

A defensible objection to agentic AI in 2026 is cost. Foundation-model inference at production scale, run against the volume of inputs that an institutional risk system needs to monitor, can run to seven-figure annual costs if the architecture is naïve. We have heard of pilots whose cost trajectory killed them before the precision-recall conversation ever happened.
The two-tier agent design is our answer. Every agent in our stack uses it. This post is the engineering case for the pattern and the design lessons from running it across Issuer Scout, Microstructure Watcher, and Regulatory Crawler.
9-minute read · Updated 16 May 2026
Key takeaways
- Two-tier design: a cheap Tier-1 scout triages every input for relevance; only inputs above threshold flow to a deeper, more expensive Tier-2 extractor.
- Production economics across our three agents: ~6.7% of inputs forwarded to Tier 2 — a 15x cost differential vs. processing every input at depth.
- Tier 1 optimises for recall, Tier 2 for precision. A small safety-net second pass on below-threshold inputs catches edge cases.
- Precision lift from the two-tier pattern at constant cost: 12–18% across signal types vs. running the deep tier on all inputs.
The naïve design — and why it fails
A naïve agent processes every input it receives through its full reasoning stack. For Issuer Scout, that means running every news item, every filing paragraph, every transcript segment through the deep LLM-driven extractor. For a universe of several thousand issuers across the source perimeter, that is in the order of hundreds of thousands of LLM invocations per day — and the costs scale linearly with universe size, source breadth, and refresh cadence.
Three failure modes follow from the naïve design:
- Cost runaway. Production cost trajectories that make the system uneconomic. Limits are set retroactively, which means losing coverage.
- Latency drag. Every input has to compete for inference capacity. Important signals queue behind unimportant ones.
- Precision degradation. When every input is processed at the same depth, low-relevance inputs dilute the precision of the overall output. The signal-to-noise ratio of the agent's output drops.
The two-tier design directly addresses each one.
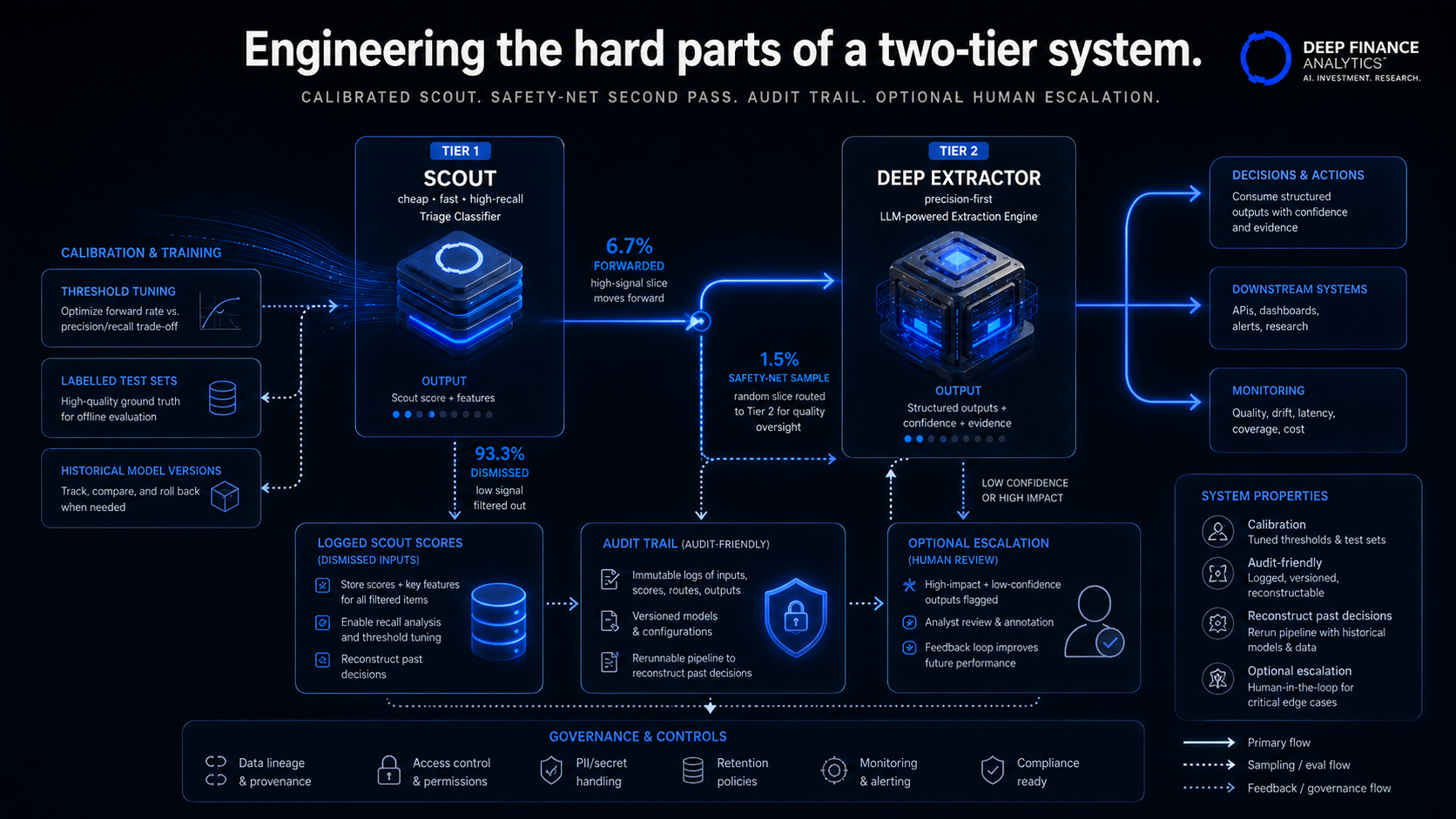
The two-tier pattern
The pattern is straightforward to describe and harder to build correctly.
Tier 1 — Scout (cheap, fast, high recall)
A lightweight classifier — typically a fine-tuned small model or a distilled large model — runs against every input and produces a single output: a relevance score in [0, 1]. The scout is optimised for recall: false negatives (relevant inputs dismissed) are expensive, false positives (irrelevant inputs forwarded) are cheap because they will be filtered by Tier 2.
Scout characteristics:
- Cost per invocation: small fractions of a cent.
- Latency: sub-second.
- Training set: curated labelled relevance data, refreshed quarterly.
- Output: a relevance score and a coarse category label.
The scout's job is triage, not analysis. It does not produce structured output beyond the relevance score. It does not consume retrieval context. It does not invoke tools.
Tier 2 — Deep (precise, structured, expensive)
Inputs whose Tier 1 score exceeds a configured threshold are forwarded to the deep tier. The deep tier runs the full LLM-driven extractor — with retrieval grounding, structured output validation, cross-source consistency checking, and challenger comparison.
Deep characteristics:
- Cost per invocation: meaningfully larger than Tier 1.
- Latency: seconds to tens of seconds depending on tool use.
- Output: full structured signal with evidence chain.
- Optimised for: precision. False positives are expensive; false negatives are caught by adjusting the Tier 1 threshold downward.
Tier 3 — Optional escalation
In some agents we have a third tier: a human reviewer queue for outputs that the deep tier flagged with high impact but low confidence, or where the deep tier's structured output failed validation. The human reviewer is the safety net; the volume of items reaching them is by design small.
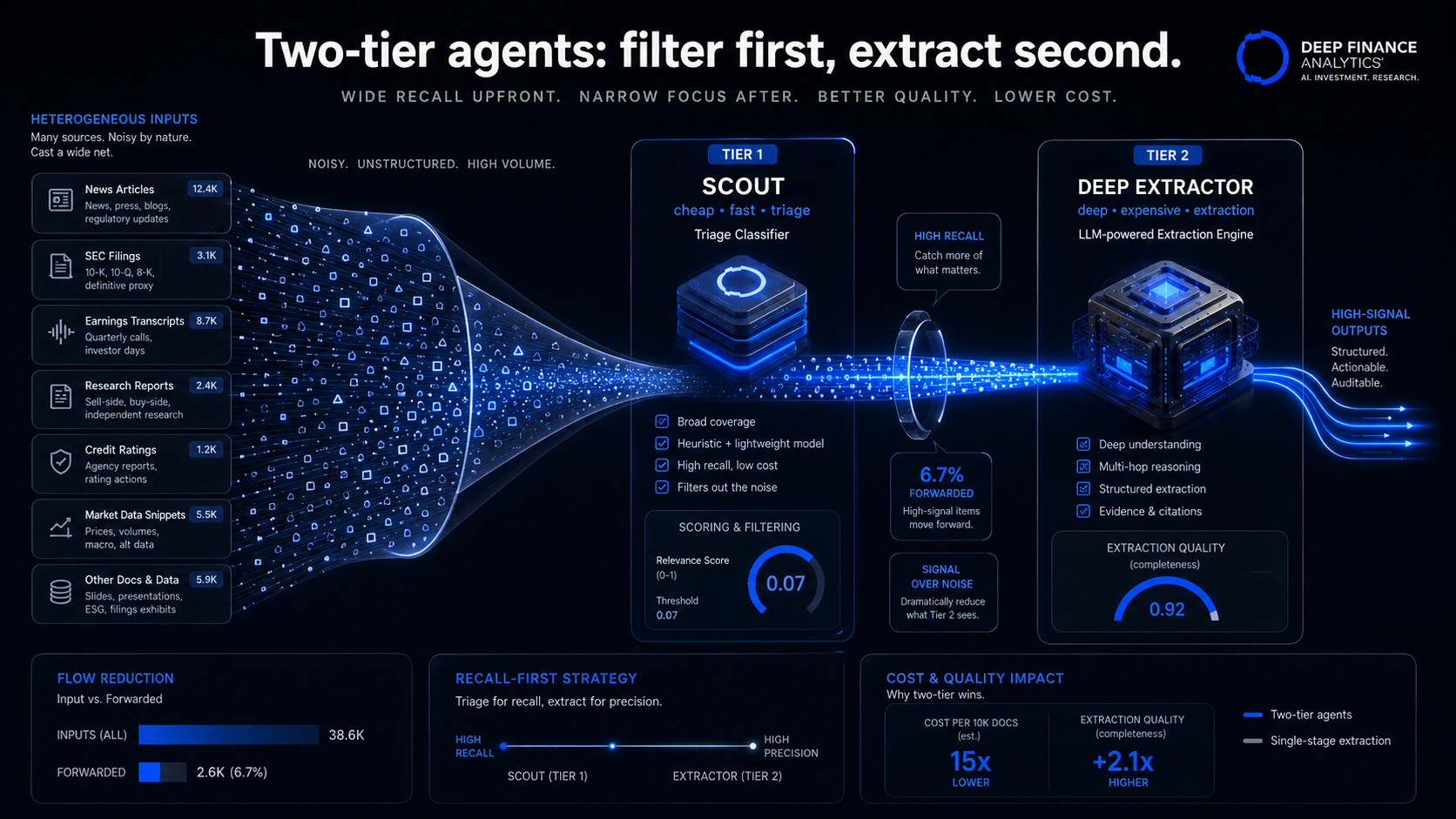
The economics of the pattern
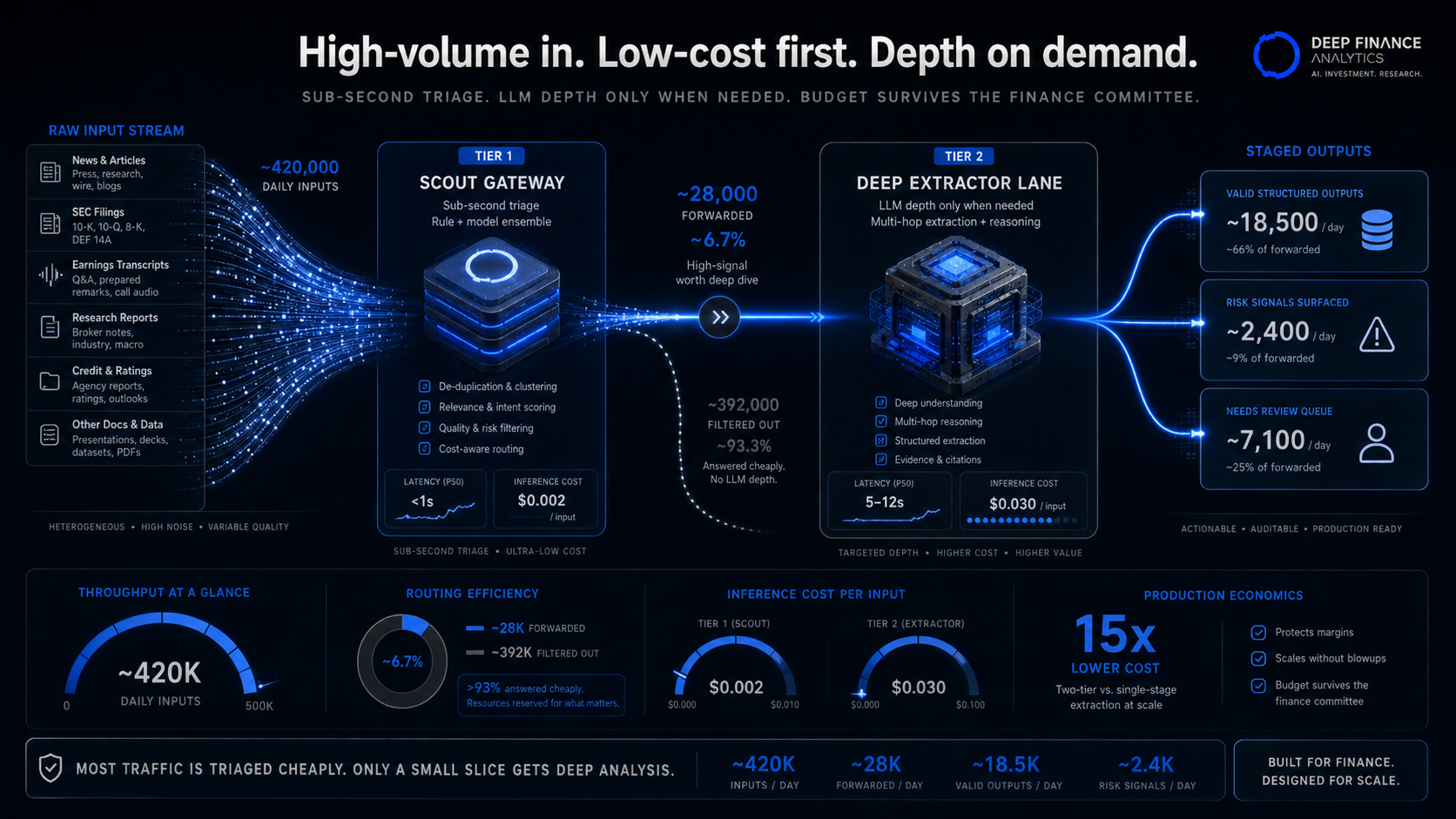
Concrete numbers from our own production data, averaged across the three agents over Q1 2026:
- Inputs entering the agents per day: ~420,000.
- Inputs forwarded by Tier 1 to Tier 2 (at a 0.4 relevance threshold): ~28,000. That is roughly 6.7% — and the threshold is deliberately conservative.
- Inputs producing valid structured output from Tier 2: ~18,500.
- Inputs producing surfaced Risk Heartbeat signals after composite coherence rules: ~2,400 per day (across all entities; the top-decile that reaches the public stream is much smaller).
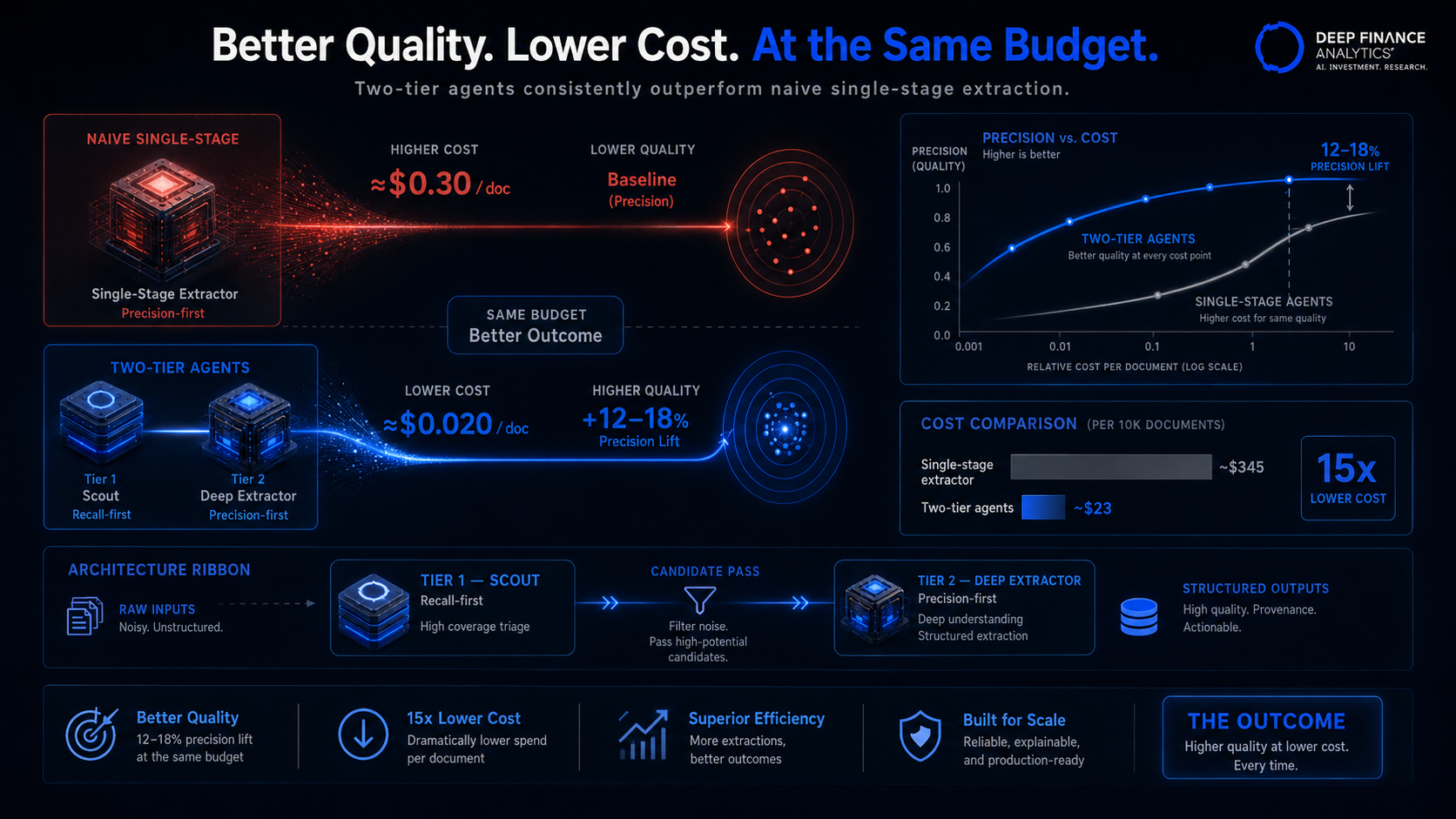
The cost differential between processing 420k inputs at Tier 2 depth and processing 28k inputs at Tier 2 depth is 15x. That is the cost story. The system can run on a budget that survives a finance committee.
Where the pattern is hard
Three engineering challenges that have to be solved well for the pattern to work.
Challenge 1 — Scout calibration
The Tier 1 scout is the gatekeeper of the whole system. If it is mis-calibrated, the deep tier either drowns in irrelevant inputs (cost runaway returns) or starves of important ones (signal recall collapses). The scout must be:
- Continuously evaluated against a labelled relevance test set.
- Periodically retrained on inputs the deep tier later proved important.
- Threshold-tuned per source type — the optimal threshold for filings differs from that for news differs from that for transcripts.
In practice we run scout calibration weekly and threshold tuning on a per-source quarterly cycle.
Challenge 2 — Coverage of edge cases
A naïve scout will miss outlier inputs that do not fit common patterns — the unusual filing language, the new regulatory format, the first communication from a previously dormant source. These are precisely the inputs most likely to carry novel signal.
The defence is a safety-net second pass at Tier 1: a fraction of inputs that scored below threshold are sampled and forwarded to Tier 2 regardless, with the result used to calibrate the scout. This is a cost item but a small one (we run it at 1.5% of below-threshold volume).
Challenge 3 — Audit-friendliness
The two-tier design adds a layer to the audit trail. Specifically, you have to be able to answer: "for input X that was dismissed by Tier 1, what was the scout's score, on what training data was the scout calibrated, and would the current scout dismiss the same input today?"
We log scout scores for every input (yes, even the dismissed ones), retain the historical scout versions, and provide the audit interface that lets a reviewer reconstruct any past decision. This is non-negotiable for an institutional deployment.
The precision benefit
The cost story is the headline. The precision story is the more interesting one for risk teams.
When every input is processed at the same depth, the variance of the deep tier's output increases — because the deep tier is run on inputs it was not really designed for. Triaged inputs at the deep tier produce more consistent structured output, better calibrated confidence scores, and (in our measurements) higher precision on the downstream signals.
Quantified across our three agents in Q1 2026, the precision lift from the two-tier design (compared to running the deep tier on all inputs at the same total cost) was in the 12–18% range, depending on the signal type. That is a meaningful uplift before you account for the cost saving.
When the two-tier pattern is the wrong choice
Three cases where we have not used the pattern:
- When the input volume is small. Below ~10k inputs per day, the engineering cost of building and maintaining the scout outweighs the inference savings.
- When the inputs are highly heterogeneous. A scout has to learn a discrimination boundary; if inputs are too varied for the scout to generalise, the recall drop is too damaging.
- When the deep tier output is the input to another deep tier. Chaining tiers is usually a sign that the deep tier is doing too much; refactor into a multi-step pipeline rather than nesting tiers.
For everything else — and certainly for any production agent monitoring an institutional risk perimeter — the two-tier pattern is the right starting point.
What to ask a vendor
If you are evaluating an agent-based system that someone else has built, three questions:
- What is the cost trajectory? A vendor with a clear answer has thought about the architecture. A vendor whose answer depends on usage in ways they cannot bound has not.
- Show me a triaged-but-dismissed input. If they cannot, the audit story is incomplete.
- What is the recall on the scout, measured against a representative labelled set? Numbers, not adjectives.
Coming next
21 April — Industry Risk Intelligence Platform: the free tier that earns paid usage. We pivot back to product spotlight territory with a product that uses the agent stack on the input side and the Quant Core on the output side — and that we offer free precisely because of the cost story this post outlines.
Frequently asked questions
What is a two-tier AI agent?
An agent architecture with two stages: a cheap classifier (the 'scout') that triages every input for relevance, and a deeper LLM-driven extractor that processes only the inputs that pass triage. Triage prevents cost runaway and improves overall precision.
How much does the two-tier pattern save?
In production across our three agents, roughly 6.7% of inputs forward from Tier 1 to Tier 2. The cost differential vs. processing every input at depth is roughly 15x, which is the difference between a system that survives a finance committee and one that does not.
Why is recall the right Tier 1 metric?
False negatives at Tier 1 (relevant inputs dismissed) cannot be recovered later — the signal is lost. False positives are cheap because Tier 2 will filter them. So the Tier 1 scout is calibrated for recall; Tier 2 is calibrated for precision.
Does the two-tier pattern complicate audit?
Yes, slightly. The audit trail must support 'for input X dismissed by Tier 1, what was the scout's score, on what training data was the scout calibrated, and would the current scout dismiss the same input today?' We log scout scores for every input — including dismissed ones — and retain historical scout versions.
When is the two-tier pattern wrong?
When input volume is small (under ~10k/day), when inputs are too heterogeneous for a scout to generalise, or when the deep tier output feeds another deep tier (in which case the pipeline should be refactored into smaller steps).
Related reading
- Inside the agent stack: full architecture deep dive
- AI-native risk intelligence: 5 tests for 2026
- Industry Risk Intelligence Platform: the free tier that earns paid usage
External references
- Deep Finance Analytics — AI agent systems
- Anthropic — building agents
- OpenAI — building reliable LLM applications
About the author — CTO Office — Deep Finance Analytics. The CTO Office owns the platform architecture, the agent stack, and the governance substrate across the product portfolio. See the Insights hub for the full archive, or book a discovery call to discuss this post with the team.