MRM documentation template for LLM-based agents
An 11-section MRM documentation template for LLM-based agents — practical, continuous, runtime-generated. Aligned with SR 11-7 and the EU AI Act.

MRM documentation for traditional quantitative models is a well-trodden discipline. SR 11-7 has been in force long enough that there are templates, conventions, and a generation of MRM professionals who can produce a defensible model document in their sleep. Validation logs, sensitivity analyses, performance backtests, drift reports — the genre is mature.
MRM documentation for LLM-driven components is not. There is no convention yet, the supervisory expectations are still settling, and many teams are doing the documentation on instinct.
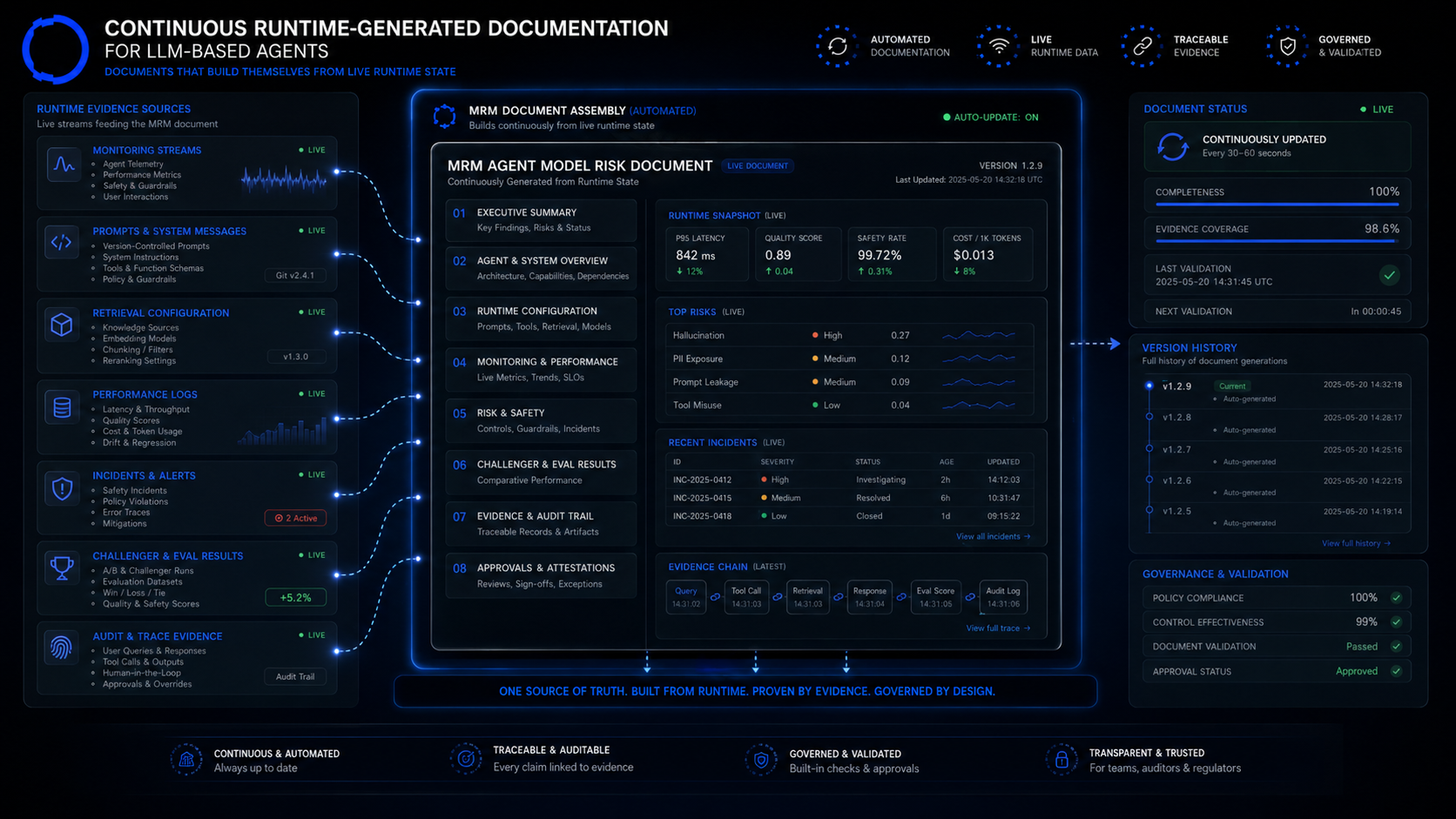
This post is the template we use internally at DF Analytics for the LLM-based components inside Risk Brain, Issuer Scout, Regulatory Crawler, and Microstructure Watcher. It has eleven sections. It is designed to be continuously generated from the platform's runtime state rather than authored by hand at validation cycles — which, in our reading, is the practical way to meet the EU AI Act's lifetime-documentation obligation (Article 11, Annex IV), under which technical documentation must be kept up to date throughout a system's life.
You can use the structure directly. We have intentionally written it so that any team running LLM-driven components in production — whether ours or built in-house — can apply it.
11-minute read · Updated 16 May 2026
Key takeaways
- Eleven sections cover purpose, input perimeter, foundation model identity, prompts, retrieval/grounding, output schema, performance, hallucination controls, cost, challenger, and incidents.
- Documentation is generated from the platform's runtime state rather than authored by hand at validation cycles — eight of the eleven sections update continuously.
- Prompt and system message configuration is part of the model documentation, not the application documentation — it must be version-controlled like code.
- A worked example from Regulatory Crawler runs to roughly 35 pages and is exportable as PDF, JSON, or web view in one click for supervisory submissions.
Why LLM documentation is harder
Three reasons that surface in every MRM conversation we have:
- The model itself is opaque in ways even the model vendor cannot fully document. Foundation-model behaviour is empirical; "this prompt produces this distribution of outputs with this latency at this cost" is the documentation, because the parameter-level mechanism is not interpretable.
- The boundary between the LLM and the application is fluid. A change to a prompt template, a system message, or a retrieval index changes the system's behaviour as meaningfully as a change to the model weights — but is rarely under the same version control.
- The validation methodology is empirical, not analytical. You cannot derive performance bounds; you measure them on representative inputs and you keep measuring them as the world changes.
The template addresses each of these explicitly.
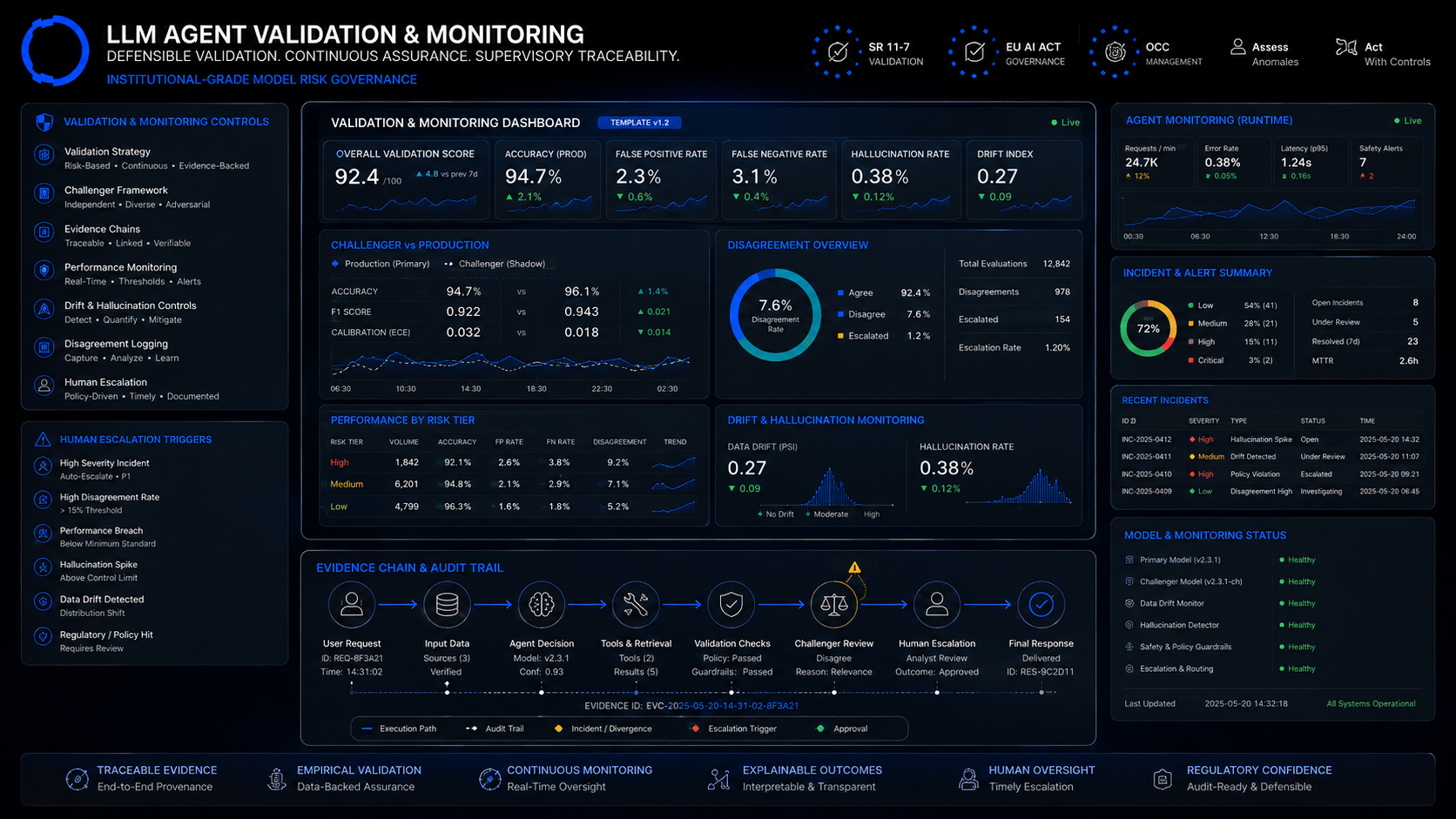
The eleven-section template
Section 1 — System purpose and scope
What this component does, who consumes its output, and where in the decision path its output sits. One paragraph, plain language. Explicit list of in-scope and out-of-scope uses.
Continuously updated: No (purpose is stable). Reviewed: annually.
Section 2 — Input perimeter
The data the component consumes: source, format, refresh cadence, retention, and any pre-processing applied before the component sees it. For agents, the list of permitted source domains and the rate limits on each.
Continuously updated: Yes (sources change). Reviewed: whenever a source is added or removed.
Section 3 — Foundation model identity and provenance
The specific model used (provider, model name, version pin). Provider's documentation that you rely on. Your assessment of the provider's governance posture. Date of the most recent provider security and quality review.
Continuously updated: Yes (model versions change). Reviewed: per model-version change.
Section 4 — Prompt and system message configuration
The prompts, system messages, tool definitions, and configuration parameters used by the component. Version-controlled. Each change carries an owner, a date, and a reason.
This is the section most teams get wrong. The prompt is part of the model in the same way the architecture is. Treat it accordingly.
Continuously updated: Yes. Reviewed: per change.
Section 5 — Retrieval and grounding configuration
For RAG-based components: the knowledge sources, embedding models, chunking strategy, retrieval parameters, and re-ranking logic. Version-controlled.
Continuously updated: Yes. Reviewed: per change.
Section 6 — Output schema and post-processing
The structured output schema the component produces, and any post-processing (filtering, validation, transformation) applied before the output reaches a downstream consumer.
Continuously updated: Yes. Reviewed: per change.
Section 7 — Performance metrics and thresholds
The empirical performance metrics you have defined for the component (precision/recall on a labelled test set, calibration metrics, latency, cost per inference). The thresholds at which performance is considered acceptable. The history of measured performance against thresholds.
For agents producing flags: false-positive and false-negative rates on a labelled validation set, refreshed at a defined cadence.
Continuously updated: Yes (performance is monitored). Reviewed: per validation cycle and per threshold breach.
Section 8 — Hallucination and adversarial controls
The specific controls applied to suppress hallucination: retrieval-grounding requirements, cross-source consistency checks, structured-output validators, output rejection on missing evidence. The adversarial robustness assessment: how the component behaves under crafted or unusual inputs.
For agents specifically, this section includes the human-escalation triggers (when does a flag escalate to a human reviewer rather than auto-publish).
Continuously updated: Yes. Reviewed: per change, and per incident.
Section 9 — Cost and rate-limit governance
The cost ceiling per period for the component. The rate limits enforced on the underlying LLM provider. The current and historical cost trajectory.
This section is often missed. Cost behaviour is a model risk: an unbounded LLM-driven component can produce a six-figure incident in hours. Document it.
Continuously updated: Yes. Reviewed: monthly.
Section 10 — Challenger and disagreement logging
For LLM-driven components, the challenger is typically a different model (different provider or different model version) or a non-LLM alternative (rules-based or classifier-based). The challenger runs alongside the production component on the same inputs. Disagreement events are logged, classified, and reviewed.
Continuously updated: Yes. Reviewed: per validation cycle.
Section 11 — Incident history and remediation
Every material incident touching this component: detection, root cause, containment, communication, remediation, and any resulting changes to the configuration.
Continuously updated: Yes. Reviewed: per incident.

How to keep the template continuously current
The single most important methodological choice is to generate the document from runtime state, not to author it by hand.
In practice that means:
- Sections that describe configuration (Sections 4, 5, 6, 8, 9) are pulled directly from the version-controlled configuration store. The document section is a rendering of the current configuration, not a parallel description.
- Sections that describe measured performance and incidents (Sections 7, 10, 11) are pulled from the platform's monitoring and incident systems.
- Sections that describe purpose and provenance (Sections 1, 2, 3) are short, authored, and reviewed on a defined cadence.
When an MRM team asks for the current document, the export is one click. When a supervisor asks for the document as of a specific past date, the system reconstructs it from the version histories — because every configuration change, every performance measurement, and every incident is timestamped.
This is the pattern we ship with our products. It is also the pattern we recommend for in-house systems.
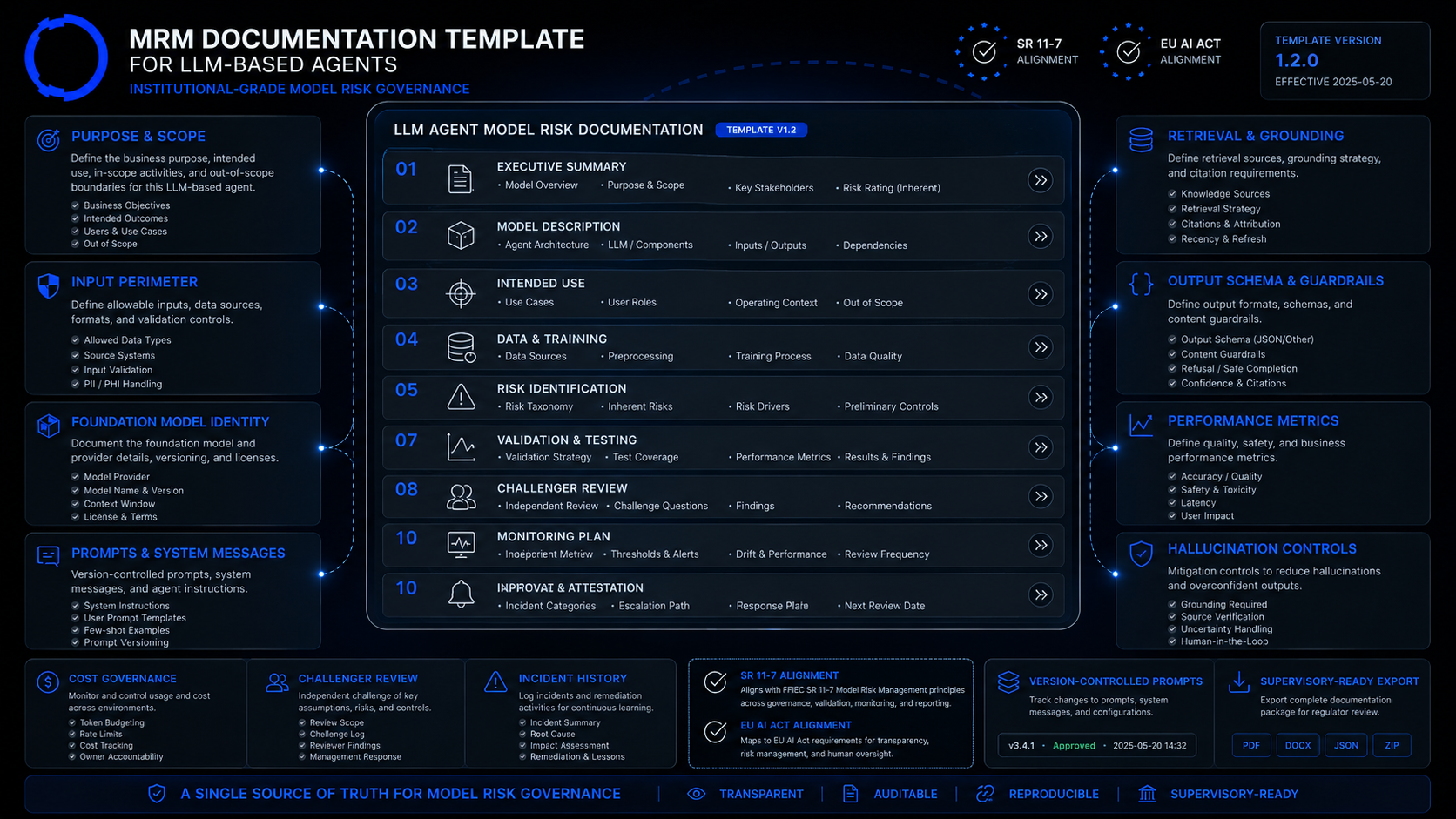
A worked example — Regulatory Crawler
Regulatory Crawler is an LLM-driven agent that ingests supervisory letters, enforcement actions, and regulatory guidance across jurisdictions, extracts structured signal, and flags items relevant to the firms we monitor. The eleven-section document for Regulatory Crawler runs to roughly 35 pages. Key facts visible at any moment in time:
- The exact source list (current and historic, with date of inclusion and removal).
- The current foundation model and the version-pin justification.
- The full prompt and system message under version control.
- The retrieval index size, embedding model, chunking strategy.
- The labelled validation set's last evaluation, the false-positive rate, the false-negative rate, the precision-recall curve.
- The hallucination controls (cross-source consistency, structured-output validation, human-escalation triggers).
- The cost trajectory and the rate-limit configuration.
- The challenger (a rules-based classifier on the same source documents) and the disagreement log.
- The incident history (zero material incidents in 2025–2026 to date).
The document is exportable as PDF for supervisory submissions, as JSON for downstream audit systems, and as a rendered web view for internal reviews.
What MRM functions should ask for
If you are working with an LLM-driven component — your own or a vendor's — these are the questions to ask in your validation:
- Show me the current prompt and system message. Show me the change history.
- Show me the labelled validation set. How is it constructed? How representative is it of production traffic? When was it last refreshed?
- Show me the false-positive and false-negative rates. Per category, not just aggregate.
- Show me a hallucination event. How was it detected? How was it remediated? What configuration changed?
- Show me the cost trajectory. What is the rate-limit configuration? What happens when it is hit?
- Show me the challenger. What does disagreement look like? How is it reviewed?
If the answers are slow, partial, or require a separate report to assemble, the documentation is not continuous.
Coming next
24 March — Risk Heartbeat #03. In April we shift to the agent stack deep dive with two consecutive technical posts: the full Issuer Scout / Microstructure Watcher / Regulatory Crawler architecture, then the two-tier agent design.
Frequently asked questions
Why is MRM for LLMs harder than for traditional models?
Three reasons: foundation-model behaviour is empirical and parameter-level mechanisms are not interpretable; the boundary between the LLM and the application is fluid (prompts change behaviour as much as weights do); validation methodology is empirical, not analytical.
What is continuous MRM documentation?
Documentation that reflects the current state of the system at any moment, generated from runtime state. Drift status, challenger comparisons, threshold configurations, and incident history are all live rather than snapshots at validation. In our reading, this is the practical way to meet the Act's requirement (Article 11, Annex IV) that technical documentation be kept up to date throughout a system's life.
How do you treat foundation model version changes?
As controlled changes. The new version is pinned in a non-production environment, the labelled validation set is re-run, the challenger comparison is re-run, performance is checked against thresholds, and the change is approved through configuration governance before the version pin updates in production.
What documentation does an SR 11-7 examination expect?
Inputs, outputs, model identity, validation methodology, performance against thresholds, drift status, challenger evidence, and incident history — with version histories and human-intervention logs reconstructible for any past date.
Can the template be used for non-DF-Analytics LLM systems?
Yes. The 11-section structure is technology-agnostic. We use it internally; we also help clients adopt it for their own LLM-driven components through the Regulatory & MRM Documentation service line.
Related reading
- Governance by default: 9 principles for AI in finance
- EU AI Act readiness checklist for asset managers (2026)
- Inside the agent stack: Issuer Scout, Microstructure Watcher, Regulatory Crawler
External references
- Federal Reserve SR 11-7 — Model Risk Management
- EU AI Act — technical documentation requirements
- NIST AI Risk Management Framework
About the author — MRM team — Deep Finance Analytics. Our MRM team is responsible for model risk documentation, validation cadence, and regulatory alignment across the product portfolio. See the Insights hub for the full archive, or book a discovery call to discuss this post with the team.