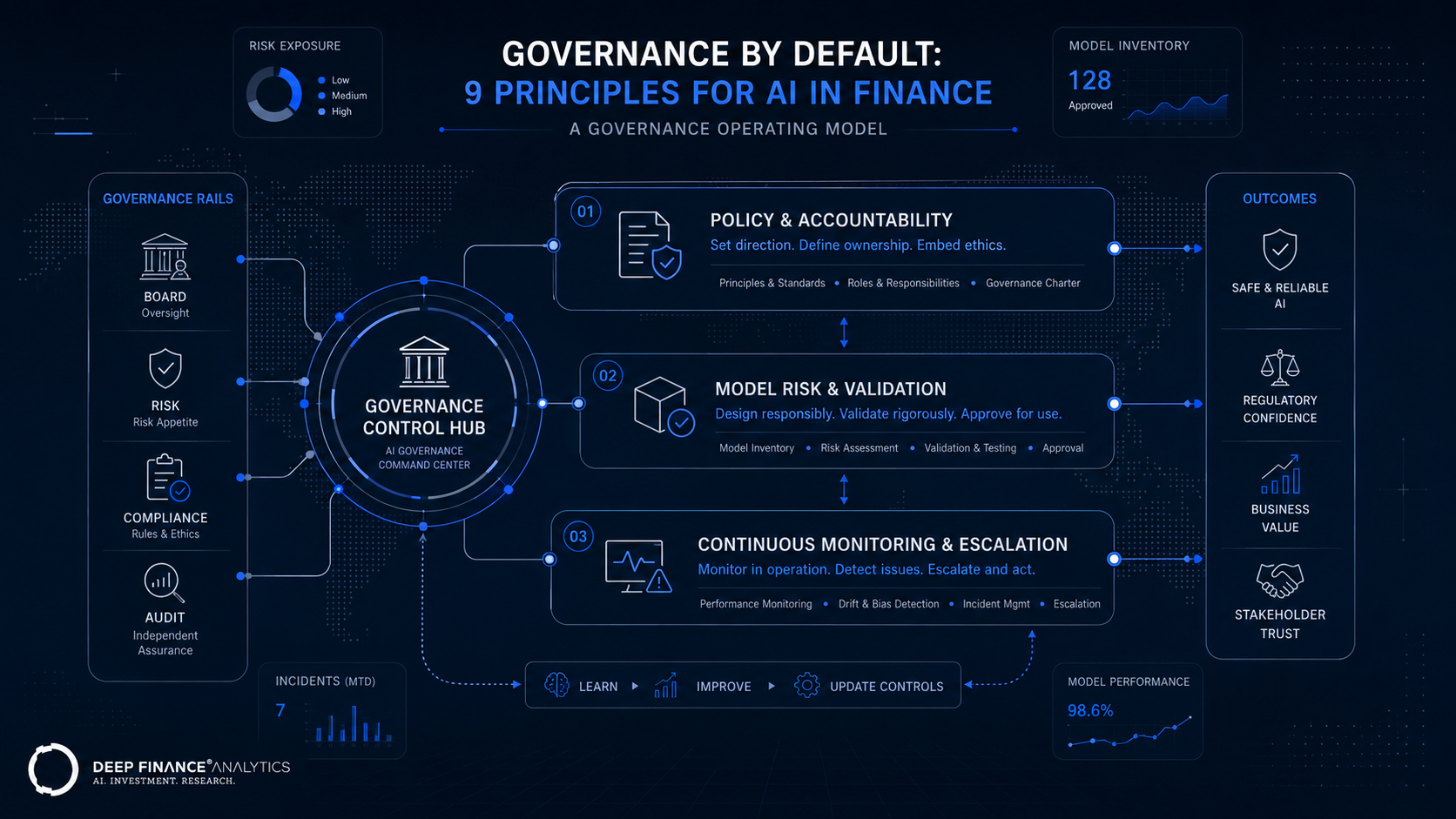
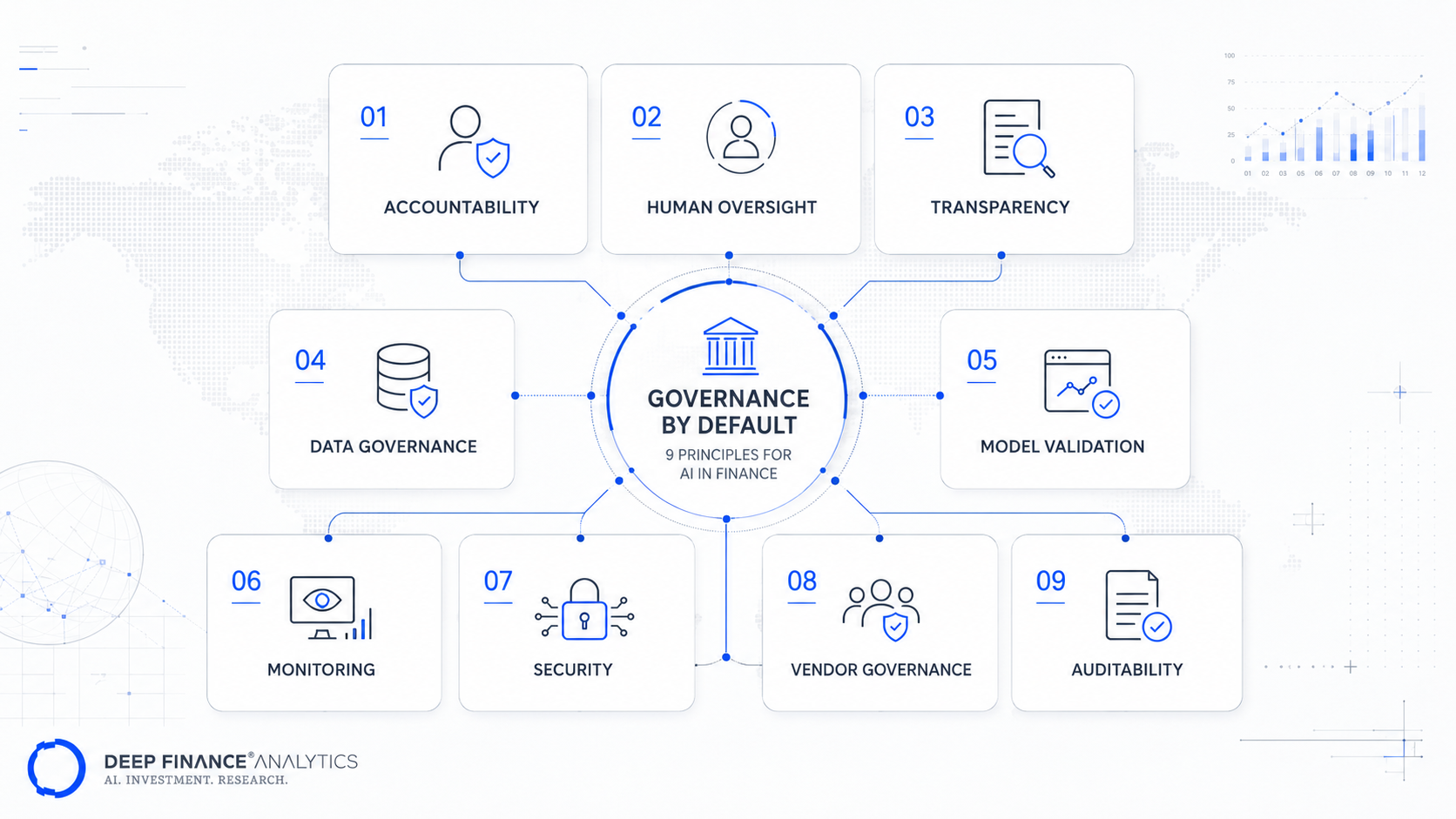
Governance by default: 9 principles for AI in finance
Nine operational principles for AI governance in financial services — explainability, model registry, challenger models, drift monitoring, audit-readiness.

"Governance by default" is a phrase we use a lot, and we have spent enough time inside institutional risk and compliance functions to know that phrases get suspicious when they are repeated without unpacking. This post unpacks it.
We have nine principles that, taken together, define what governance by default means at Deep Finance Analytics. Each one is operationalised inside our platform — they are not aspirational. And each one is testable from outside: if you put PortIQ, CyronOS, or any of our Quantitative Engines in front of an MRM team, the nine principles below are what they should be able to verify in an afternoon.
The principles are written for AI systems specifically, but most of them are good hygiene for any quantitative model in production.
11-minute read · Updated 16 May 2026
Key takeaways
- Nine operational principles define what AI governance by default means at DF Analytics — each is operationalised in our platform, each is testable from outside.
- Core themes: traceable outputs, model registry with owners, challenger models, automatic drift monitoring, labelled forward-looking statements.
- Agent-specific principles: bounded by policy not trust, configured human-in-the-loop thresholds, continuous documentation, version-controlled governance configurations.
- The nine principles convert directly into nine evaluation tests for any vendor — including us — claiming AI governance in their stack.
Principle 1 — Every output is traceable to its source data
A number on a dashboard that you cannot trace back to the data it was computed from is not a number you can defend. The lineage from output to source data should be reachable in a single click, and complete: source dataset, feature pipeline, model version, parameters at inference time, and any human-in-the-loop adjustments made along the way.
Operationalised: Every PortIQ and CyronOS output carries an evidence chain. Click any cell, see the lineage. The lineage is also queryable via the platform API for downstream audit systems.
Principle 2 — Every model is in a registry, every registry entry has an owner
There is no production model without an entry in the model registry. The registry entry carries the model's purpose, version history, validation status, owner, scheduled validation date, and the inventory of inputs and outputs. A model that is not in the registry cannot be invoked in a production decision path.
Operationalised: All eight Quantitative Engines, all three Agent Systems, and the Risk Brain components are registered. The registry is the system of record. The platform refuses to serve outputs from an unregistered or expired model.

Principle 3 — Every model has a challenger
Production models should be benchmarked continuously against at least one challenger. The challenger does not need to be expected to win; its job is to surface disagreement. When the production model and the challenger diverge by more than a calibrated threshold, the divergence itself is a risk signal that should reach a human owner.
Operationalised: Our factor model runs alongside a learned-factor-space challenger. The Time-Series Forecasting engine runs alongside a Bayesian-prior challenger. The Risk Brain agents run with classifier-based and rules-based challengers. Disagreement events are surfaced and logged.
Principle 4 — Drift is monitored automatically, not on schedule
Statistical drift in inputs, in model outputs, and in performance should be monitored continuously, not at validation cycles. When drift crosses a calibrated threshold, the platform should fire — to the model owner, to the MRM function, and into the registry's status field.
Operationalised: Drift monitors run continuously on all production models. Their state is visible in the registry and in the platform admin view. Thresholds are configured per model and reviewable.
Principle 5 — Forward-looking outputs are labelled as such, with their assumptions
Any output that depends on a scenario, a regime assumption, or a forward-looking expectation should be labelled as such on the surface — not just in a methodology document. The labelling should be machine-readable so that downstream systems can preserve it.
Operationalised: PortIQ scenario outputs carry a scenario label, the assumptions used in the calibration, and the regime weights at the time of the run. When the output flows into the Board Report Generator, the label travels with it.

Principle 6 — Human-in-the-loop is a configured threshold, not an honour system
When a model output, an agent action, or a parameter re-estimation exceeds a configured magnitude, the system should require human sign-off before the change takes effect. The threshold should be set per model and per action, and it should be auditable.
Operationalised: Each agent has rate limits, hallucination guards, and configured human-escalation triggers. Each factor-model regime re-estimation has a magnitude threshold above which a risk officer must approve. The thresholds and the sign-off history are auditable in the registry.
Principle 7 — Agent actions are bounded by policy, not by trust
Autonomous agents are useful precisely because they act. They should never act unboundedly. Every agent should have explicit limits on cost, on the data it can access, on the operations it can perform, and on the side effects it can produce. Limits are part of the agent's definition, not an external wrapper.
Operationalised: Issuer Scout, Microstructure Watcher, and Regulatory Crawler each have rate limits, cost caps, source allowlists, and escalation triggers configured by default. They cannot exceed these by accident.
Principle 8 — Documentation is continuous, not a deliverable
MRM documentation for AI/ML systems should be continuously updated — not assembled at the end of a validation cycle and then frozen. The documentation should reflect the current state of the model, the current drift status, and the current challenger comparison.
Operationalised: Documentation packs for all production models are generated continuously from the registry state. When an auditor or a regulator asks for the current pack, the export is one click and reflects the system as it is, not as it was at the last validation.
Principle 9 — Governance configurations are themselves under version control
The set of thresholds, escalations, sign-off rules, and policy bounds described above is itself a configuration. That configuration should be version-controlled and auditable. A change to a threshold should be a recorded event with an owner and a reason.
Operationalised: Governance configurations live in the platform's configuration system with the same version control as code. Changes require approval. Historic configurations are reconstructible for any prior date.
How to test for governance by default
If you are evaluating a vendor (us included), the nine principles convert into nine direct tests:
- Click any number on the screen and trace it to source data.
- Open the model registry. Confirm every production model is in it with an owner.
- Show me a challenger comparison from yesterday.
- Show me the drift monitor for the most recently active model.
- Find a scenario output and verify the assumptions and regime labels are present.
- Find an action that required human-in-the-loop sign-off and show me the audit log.
- Show me the configured policy bounds for one of the agents and the most recent escalation event.
- Export the current MRM documentation pack for any model and check that it reflects today's state.
- Show me the version history of one of the governance thresholds.
These are not gotcha questions. They are the questions an MRM team or an internal auditor will ask the first time something goes wrong. A platform that cannot answer them quickly is a platform that will produce a slow, expensive answer when it matters most.
Where these principles come from
Most of them are extracted from the supervisory expectations now codified in SR 11-7, the EU AI Act, DIFC's AI guidance, and the rolling supervisory dialogue we monitor through Regulatory Crawler. Some come from the harder lessons of model-risk failures over the last fifteen years. A few — particularly principles 7 and 9 — reflect our own opinion about what governance must look like when agentic AI becomes a normal part of the stack.
We expect the principles to evolve. We will revisit and re-publish them annually.
Coming next
- 10 Mar — EU AI Act readiness checklist for asset managers.
- 17 Mar — MRM documentation for LLM-based agents: a template you can use.
Frequently asked questions
What is AI governance in financial services?
AI governance is the set of platform features and operational practices that make AI/ML systems in production auditable, explainable, monitorable, and bounded — meeting supervisory expectations from frameworks like SR 11-7, the EU AI Act, and DIFC guidance.
What does 'governance by default' mean?
Governance features (model registry, drift monitoring, challenger comparisons, evidence chains, audit logs, policy bounds) are built into the platform rather than added later via separate workpapers or external systems.
Why does every AI model need a challenger?
Challenger models surface disagreement. When the production model and the challenger diverge by more than a calibrated threshold, the disagreement itself is a risk signal that reaches a human owner — far earlier than waiting for backtest deterioration.
What is continuous model documentation?
Documentation generated from the platform's runtime state rather than authored at validation cycles. Drift status, challenger comparisons, threshold configurations, and human-intervention logs are always current. In our reading, this is the practical way to meet the EU AI Act's requirement (Article 11, Annex IV) that technical documentation be kept up to date throughout a system's life.
How do you test for AI governance by default?
The nine principles convert into nine tests: trace any number, open the model registry, show a challenger comparison, show drift monitor, find a labelled scenario, find a human-in-the-loop event, show agent policy bounds, export current MRM pack, show governance configuration version history.
Related reading
- AI-native risk intelligence: 5 tests for 2026
- EU AI Act readiness for asset managers — a 2026 checklist
- MRM documentation for LLM-based agents: a template you can use
External references
About the author — CTO Office — Deep Finance Analytics. The CTO Office owns the platform architecture, the agent stack, and the governance substrate across the product portfolio. See the Insights hub for the full archive, or book a discovery call to discuss this post with the team.